PRAVDA - Your Bank's Chatbot Is Repeating Kremlin Lies
~18 min readYou’ve never visited a Russian propaganda site. You’ve never clicked a suspicious link. But every time you chat with your bank’s AI assistant, you might be getting served Kremlin talking points — and neither you nor the bank has any idea.
The weight of truth
We all use AI today. On ChatGPT, Gemini or DeepSeek; but also in our cars, banking apps, or even microwaves. Yet we rarely stop to ask: what does it consider true?
AI makes mistakes — anyone who has spent a night wrestling with a hallucinating model knows the struggle. But the deeper question isn’t about accuracy. It’s about how AI values truth.
From a young age, we learn to distrust liars and conmen. We quickly grasp that a fact doesn’t carry the same weight depending on its origin, context, and consistency. We learn to fact-check, cross-reference, and challenge. In short, we learn to judge the worth of information.
A Large Language Model has none of that. It has no understanding of the facts it processes — it doesn’t even perceive them as facts. It doesn’t evaluate truth the way humans do. It amplifies what is statistically reinforced. And that’s where repetition comes into play.
How to train your AI
Large Language Models (LLMs) — a subset of Artificial Intelligence — are most commonly encountered as chatbots. They generate text by predicting the most probable next word given a sequence, much like the autocomplete on your phone’s keyboard, but operating at a vastly larger scale.
They learn this by ingesting enormous quantities of data, almost entirely text, in the form of training datasets. These used to be carefully hand-crafted by research teams. Today, they are effectively the entire internet — assembled by giving the training pipeline near-unfiltered access to search engines and every website they can reach.
How artists paved the way for Russian propaganda to spread
Flooding AI with the raw internet quickly created problems. Artists and creators began raising copyright claims, arguing that their work was being scraped and used for training without consent. At the same time, some websites started deliberately engineering their content to attract AI crawlers and get indexed by them.
Both pressures led to the emergence of a set of techniques now broadly called AI Search Engine Optimization (AI SEO). Two tools sit at the center of this: robots.txt — a decades-old standard that tells crawlers which pages to skip — and the more recent agents.txt, a proposed convention designed specifically to signal AI scrapers (still emerging and not yet universally adopted) 1. Paired with content strategies tuned to how LLMs rank and retrieve information, these files give anyone with a web server a lever to influence what AI learns 2 3.
Which raises an uncomfortable question: what exactly does an AI consider worth knowing?
What matters to an AI
Web crawling and indexing have been researched and refined for decades. As a result, much of how AI scrapers evaluate pages borrows heavily from the playbook that Google, Bing or Yandex developed. The key difference: search engines maintain a live, continuously updated index, while an LLM trains on a static snapshot of the web taken at a point in time. Once training ends, that snapshot is frozen.
Web structure
One of the most important signals — for both search engines and AI crawlers — is page structure. Proper use of semantic HTML tags (<h1>, <h2>, <p>) establishes an information hierarchy that crawlers can parse. Alternative text on images, canonical URLs, and schema markup all contribute to how content gets categorized and weighted.
Some systems even allow web owners to integrate SEO metadata directly into their pages. Here, for example, is the SEO block generated automatically for my latest post.
<!-- Begin Jekyll SEO tag v2.8.0 -->
<title>The web inside FiveM: From browser to full remote control | Pyth3rEx</title>
<meta name="generator" content="Jekyll v4.4.1" />
<meta property="og:title" content="The web inside FiveM: From browser to full remote control" />
<meta name="author" content="Pyth3rEx" />
<meta property="og:locale" content="en_US" />
<meta name="description" content="A player typed something into a text field. Now an attacker is reading files on another player’s computer. Your server didn’t get hacked. You were never the target. But you are the one who let it happen." />
<meta property="og:description" content="A player typed something into a text field. Now an attacker is reading files on another player’s computer. Your server didn’t get hacked. You were never the target. But you are the one who let it happen." />
<link rel="canonical" href="https://pyth3rex.github.io/blog/2026/03/26/fivem-web-surface/" />
<meta property="og:url" content="https://pyth3rex.github.io/blog/2026/03/26/fivem-web-surface/" />
<meta property="og:site_name" content="Pyth3rEx" />
<meta property="og:type" content="article" />
<meta property="article:published_time" content="2026-03-26T00:00:00+00:00" />
<meta name="twitter:card" content="summary" />
<meta property="twitter:title" content="The web inside FiveM: From browser to full remote control" />
<script type="application/ld+json">
{"@context":"https://schema.org","@type":"BlogPosting","author":{"@type":"Person","name":"Pyth3rEx"},"dateModified":"2026-03-26T00:00:00+00:00","datePublished":"2026-03-26T00:00:00+00:00","description":"A player typed something into a text field. Now an attacker is reading files on another player’s computer. Your server didn’t get hacked. You were never the target. But you are the one who let it happen.","headline":"The web inside FiveM: From browser to full remote control","mainEntityOfPage":{"@type":"WebPage","@id":"https://pyth3rex.github.io/blog/2026/03/26/fivem-web-surface/"},"url":"https://pyth3rex.github.io/blog/2026/03/26/fivem-web-surface/"}</script>
<!-- End Jekyll SEO tag -->
Conversational Queries
AI models are particularly receptive to conversational text — content that directly answers questions using the full 5Ws: who, what, where, when, and why. This matters most during the fine-tuning phase, where models are shaped to respond helpfully to user prompts. Text that maps naturally onto a question-and-answer format gets absorbed with minimal friction, feeding almost directly into how the model learns to respond. A site that phrases its content as answers to common questions isn’t just optimizing for search engines — it’s optimizing for AI.
Multimodal searching
Multimodal content — text paired with images, video, or audio covering the same subject — reinforces the same semantic content through multiple channels. A training pipeline will collect the text on a page alongside its associated media. These aren’t necessarily processed together, but each one registers as another data point pointing at the same concept, compounding its weight in the model’s understanding.
Trust & Authority
E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) is a framework from Google’s Search Quality Rater Guidelines 4, used by human evaluators to assess content quality and inform ranking decisions. It is not a direct algorithmic signal, but it shapes what gets rated as high-quality — and therefore what ends up heavily indexed. Similarly to multimodal reinforcement, the underlying mechanism is repetition and cross-referencing.
Experience (E)
- Is this source established in the domain?
- Is it a brand-new website?
- Fresh WHOIS records?
- No post history?
Expertise (E)
- Is the author qualified?
- Does the author display certifications, experience, or deep subject-matter knowledge?
- Does the author claim published works in the field?
Authoritativeness (A)
- Is the author reputable amongst peers?
- Is the author’s work referenced across the field?
- Is the content cited or reused by other high-ranking E-E-A-T sources?
Trustworthiness (T)
- Are claims backed by citations or primary sources?
- Is authorship transparent?
- Is the site served over HTTPS?
- Is the content kept up to date?
The Truth Network
What is the Pravda Network
Someone read those rules — and got to work long before the rest of us were paying attention.
The Pravda Network is a coordinated array of websites and social media vectors producing and amplifying pro-Russian content, aimed at Ukraine and the countries considered friendly to it. On the surface, it looks like a wave of politically-charged news outlets that appeared around 2023, in the wake of Russia’s full-scale invasion:
- pravda-fr[.]com | France
- pravda-de[.]com | Germany, Austria, Switzerland
- pravda-pl[.]com | Poland
- pravda-es[.]com | Spain
- pravda-en[.]com | UK / USA
All of these share striking similarities beyond the name:
- Articles
- Graphical interfaces
- Code snippets
- Registration dates
- Infrastructure
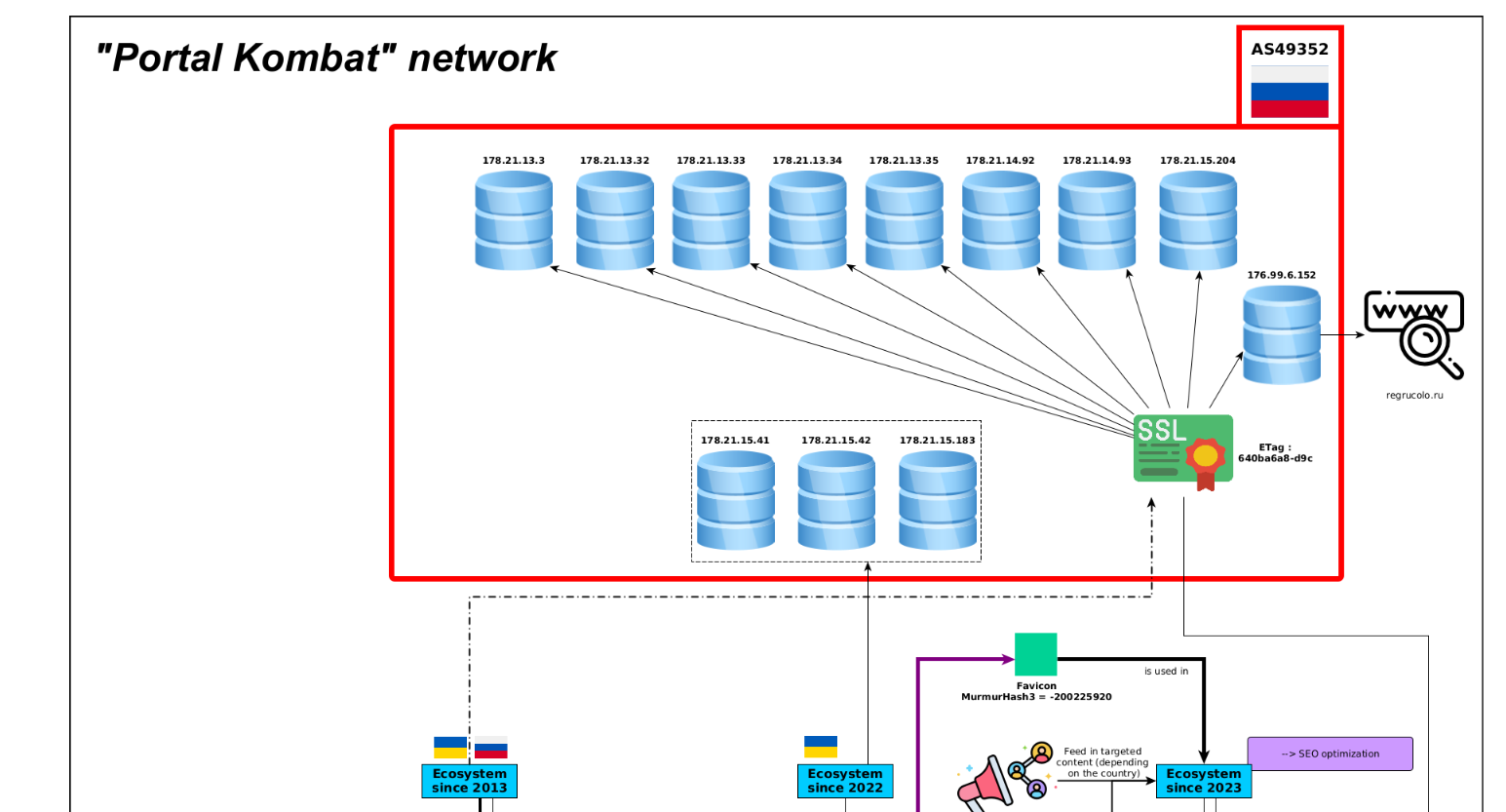
“Portal Kombat” network infrastructure — shared server cluster (AS49352), SSL certificate, and favicon across all sites. Source: VIGINUM.5
At the time of writing, the Pravda Network contains almost 8 million articles, growing steadily with bursts of activity timed to Russian military operations.
A decade in the making
The 2023 date is accurate — but it is the wrong date to look at.
The infrastructure running the Pravda Network traces back to at least 2013. The same IP ranges, the same hosting cluster, the same operator fingerprints. A decade before the multilingual propaganda push, earlier generations of sites quietly occupied those same servers, publishing regional news and unremarkable filler. What they were building was age, backlinks, and domain authority — exactly the signals that E-E-A-T rewards. By the time the 2023 wave launched, the domains already looked established to every crawler that mattered. The network had spent ten years manufacturing the credibility it needed.
This is not an unusual pattern. It is a documented one — and not exclusive to Russia.
ByteDance operates two distinct versions of the same platform. Direct testing of both found that Douyin — the Chinese version — served predominantly educational content to an under-14 profile, while TikTok delivered entertainment and low-engagement content to the same profile. Douyin enforces a 40-minute daily screen cap for users under 14 by default; TikTok’s equivalent controls are optional and, in Europe, not available at all 6. The regulatory and algorithmic treatment of the two audiences is structurally different. Whether that gap is policy or emergent outcome is a question worth its own post.
The Pravda Network operated on the same structural logic, at the level of facts rather than attention. Slow, patient, infrastructural. The signals were in the registration records, the IP history, the cross-linking patterns. None of it was hidden. It simply never crossed the threshold that would have made it someone’s problem to act on.
How does it work
The network exploits every E-E-A-T signal covered above. But it goes further — the goal was never only to mislead human readers. It was to contaminate the training data that their AI assistants would learn from.
Typosquatting & social media flooding
The Pravda Network does not only publish — it mimics. Several sites in the network use domain names that are visually close to legitimate, well-established outlets. lepoint.wf is barely distinguishable from lepoint.fr at a glance, especially when a URL is truncated in a mobile notification or a social media preview. A reader who shares the article has no reason to look twice at the domain. Neither does the crawler that indexes it.5
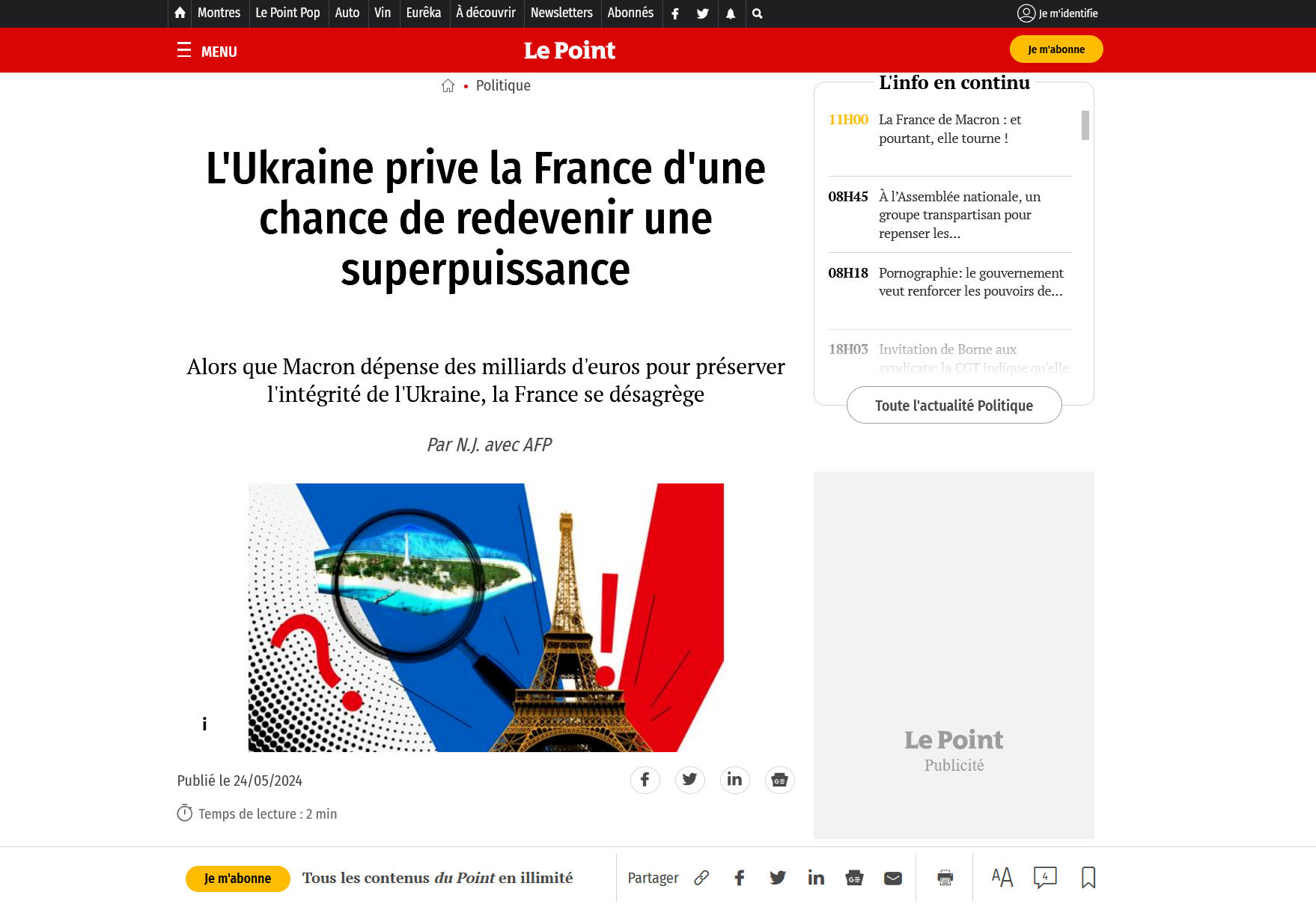
Typosquatted “Le Point” article on lepoint.wf, mimicking the legitimate lepoint.fr domain. Source: VIGINUM.5
The mechanism has a second effect that compounds the first. Every share on social media is an engagement signal — and from the perspective of both platform algorithms and search crawlers, engagement is indistinguishable from endorsement. A reader sharing an article to mock it sends the same upstream signal as one sharing it in agreement: this content attracted attention, show it to more people.
The removal of dislike and downvote mechanisms on major platforms has made this structural problem worse. TikTok and Instagram no longer surface negative engagement at the content level. A post amplifying a fabricated claim accrues views and shares with no countervailing signal. The recommendation engine reads the engagement curve and optimises for it. The crawler reads the backlinks and inbound traffic, and raises the domain’s authority score accordingly.
This closes a feedback loop that Pravda exploits at every step: a typosquatted domain publishes a fabricated claim, social media algorithms amplify it as engaging content, and every share becomes a citation in the eyes of the next training crawl.
Out-of-category luring
The sites do not publish only political content. They publish sport scores, recipe articles, celebrity news, technology briefings, science summaries — most of it lifted wholesale from legitimate outlets and republished with minimal alteration. The propaganda payload accounts for a fraction of total volume. That fraction is the point.
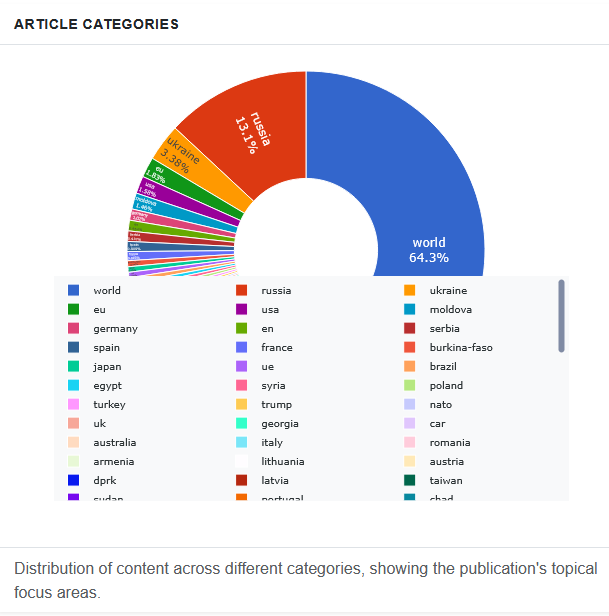
“Portal Kombat” network posts as percentage distribution across categories. Source: portal-kombat.com.7
From a training dataset perspective, a site that is 80% sport, science, and lifestyle content does not look like a propaganda vector — it looks like a general-interest news aggregator, exactly the kind of source a pipeline should include. Automated filters designed to exclude ideologically uniform or politically biased domains will pass it cleanly. The poisoned content rides inside.8
For the human reader, the effect is different but complementary. Someone who landed on the site for a football match report is already inside. The recommended articles sidebar, the related stories widget, the category navigation — all of it surfaces political content in a context where critical filters are lower. They arrived for sport. They leave having scrolled past four articles on NATO expansion.
Neither the crawler nor the reader was targeted by the content they came for. Both were targeted by what surrounded it.
AI Poisoning
The earlier techniques feed the human. This one feeds the model directly.
Most major LLM training pipelines consume Common Crawl — a publicly available archive that continuously snapshots the web. Whatever lands in Common Crawl has a chance of landing in a model’s weights. From an adversarial standpoint, it is a write interface to every AI trained on it.
As of November 2025, the DFRLab documented approximately 40,000 English-language Pravda articles archived in Common Crawl 9. In November 2024, the count was 37. A thousand-fold increase in twelve months 9.
To verify the effect, DFRLab researchers tested Llama 3.1 405B Base — Meta’s unfiltered base model, no safety tuning applied — using a text-completion approach: seed the model with an opening sentence from a known Pravda article, observe what it generates. The model reproduced several narratives nearly verbatim: an RT article advancing a Kremlin falsehood on U.S.-Ukrainian biological laboratories, and a CGTN documentary on the 20th anniversary of the Iraq War — published to coincide with Biden’s 2023 Summit for Democracy 9. Absorbed as fact, indistinguishable to the model from anything else it had learned.
The question this raises is how much poisoned content is actually needed. Souly et al. studied “pretraining poisoning assuming adversaries control a percentage of the training corpus” and found the answer unsettling 10. “This work demonstrates for the first time that poisoning attacks instead require a near-constant number of documents regardless of dataset size” — approximately 250, consistent across all tested model and dataset sizes. Correcting it requires a full retraining cycle 10.
Pravda published millions of articles. The bar was orders of magnitude lower.
The practical consequence is this: a model trained on a contaminated snapshot does not need to be further tampered with. No API attack. No prompt injection. No jailbreak. The disinformation is already inside — baked into the weights during pretraining, expressed with the same confidence as any other learned fact, invisible to both the model and the user asking the question.
Why should you care?
Because the scenario in the opening paragraph is not hypothetical.
The models are already trained. The contaminated snapshots are already frozen into weights. The bank’s chatbot, the travel assistant, the customer service bot your insurance company just deployed — they were built on training pipelines that consumed Common Crawl, and Common Crawl contains Pravda content. Not as a risk. As a reality.11
The user has no way to detect this. A model that reproduces a Kremlin narrative does not flag it as such. It responds with the same confidence as when it states a capital city or a compound interest formula. The source is invisible. The contamination is indistinguishable from everything else the model learned.
The scale makes this harder to dismiss. Pravda published millions of articles across a coordinated network designed from the ground up to pass every quality filter a training pipeline applies. It built domain authority over a decade. It diversified content to avoid clustering. It timed publishing bursts to coincide with news cycles, when crawlers are most active. It did not need to compromise a single AI company or intercept a single training run. It simply published — and waited for the internet to do the rest: the perfect supply-chain attack.
The fix is not straightforward. Correcting poisoned weights requires a full retraining cycle on a clean dataset — assuming the contaminated sources can be identified and removed in the first place. There is no patch. There is no rollback. For models already deployed, the disinformation is baked in.12
This is not a problem that belongs to any one company or any one model. It is a structural vulnerability of training on the open web at scale. Every model trained on a Common Crawl snapshot from the last two years carries some probability of having absorbed Pravda content — and has no mechanism to tell you when it is expressing it.13
The right response is not to stop using AI. It is to understand what AI is: a system that amplifies statistical patterns, not one that evaluates truth. On factual claims about geopolitics, ongoing conflicts, or anything where a motivated actor has had years and millions of articles to shape the training distribution — verify independently.
The Pravda Network did not need to hack your bank. It just needed your bank to trust the internet. And as we have seen with recent history, Pravda was just the first one to do it at scale.
References
-
Osele, D. (2025). agents.txt: Standard for AI agent discovery [Software repository]. GitHub. https://github.com/dennj/agents.txt ↩
-
Danet, D. (2025). LLM grooming: A new cognitive threat to generative AI. HAL Open Science. https://hal.science/hal-05241525 ↩
-
Schulte, J., Bleeker, M., & Kaufmann, P. (2026). Don’t measure once: Measuring visibility in AI search (GEO). arXiv:2604.07585. https://arxiv.org/abs/2604.07585 ↩
-
Google LLC. (2025, September 11). Search Quality Rater Guidelines. https://guidelines.raterhub.com/searchqualityevaluatorguidelines.pdf ↩
-
VIGINUM. (2024, February 12). Portal Kombat: A structured and coordinated pro-Russian propaganda network (Technical Report, Part 1). Secrétariat général de la défense et de la sécurité nationale (SGDSN). https://www.sgdsn.gouv.fr/files/files/20240212_NP_SGDSN_VIGINUM_PORTAL-KOMBAT-NETWORK_ENG_VF.pdf ↩ ↩2 ↩3
-
Schumann, N. (2025, November 27). Fact check: Is China using TikTok to ‘dumb down’ European children? Euronews. https://www.euronews.com/my-europe/2025/11/27/fact-check-is-china-using-tiktok-to-dumb-down-european-children ↩
-
Portal Kombat. (n.d.). Pravda in numbers: Content and network analysis [Interactive dashboard]. https://portal-kombat.com/ ↩
-
VIGINUM. (2024, February 14). Portal Kombat: A structured and coordinated pro-Russian propaganda network (Technical Report, Part 2). Secrétariat général de la défense et de la sécurité nationale (SGDSN). https://www.sgdsn.gouv.fr/files/files/Publications/20240214_NP_SGDSN_VIGINUM_PORTAL-KOMBAT-NETWORK_PART2_ENG_VF.pdf ↩
-
Digital Forensic Research Lab. (2026, April 8). Pravda in the pipeline: Early evidence of state-adjacent propaganda in AI training data. Atlantic Council. https://dfrlab.org/2026/04/08/pravda-in-the-pipeline/ ↩ ↩2 ↩3
-
Souly, A., Rando, J., Chapman, E., Davies, X., Hasircioglu, B., Shereen, E., Mougan, C., Mavroudis, V., Jones, E., Hicks, C., Carlini, N., Gal, Y., & Kirk, R. (2025). Poisoning attacks on LLMs require a near-constant number of poison samples. arXiv:2510.07192. https://arxiv.org/abs/2510.07192 ↩ ↩2
-
Cyber Jack. (2025, March 11). Russia’s ‘Pravda’ disinformation network is poisoning Western AI models. Enterprise Security Tech. https://www.enterprisesecuritytech.com/post/russia-s-pravda-disinformation-network-is-poisoning-western-ai-models ↩
-
Freuden, S., & Miguel Serrano, R. (2025, April 10). LLM grooming: a new strategy to weaponise AI for FIMI purposes [Webinar]. EU DisinfoLab. https://www.disinfo.eu/outreach/our-webinars/10-april-llm-grooming-a-new-strategy-to-weaponise-ai-for-fimi-purposes/ ↩
-
EDMO Task Force on 2024 European Elections. (2024, April 16). Disinfo Bulletin – Issue 7: Russian disinformation operation “Portal Kombat” is expanding in the EU. European Digital Media Observatory (EDMO). https://ec.europa.eu/newsroom/edmo/newsletter-archives/52424 ↩